
はじめに
最近仕事で、顧客先の連携するデータベースの状況を調査するために、そのデータベースからダンプしたCSVファイルを使って状況を調査することがあった。
適当にExcelなどでCSVファイルを開いて見ることもできたのだが、SQLが使えたほうがいいのでRDBに入れる方が良いと思った。
また、たまたま見かけた以下の資料を見つけた。
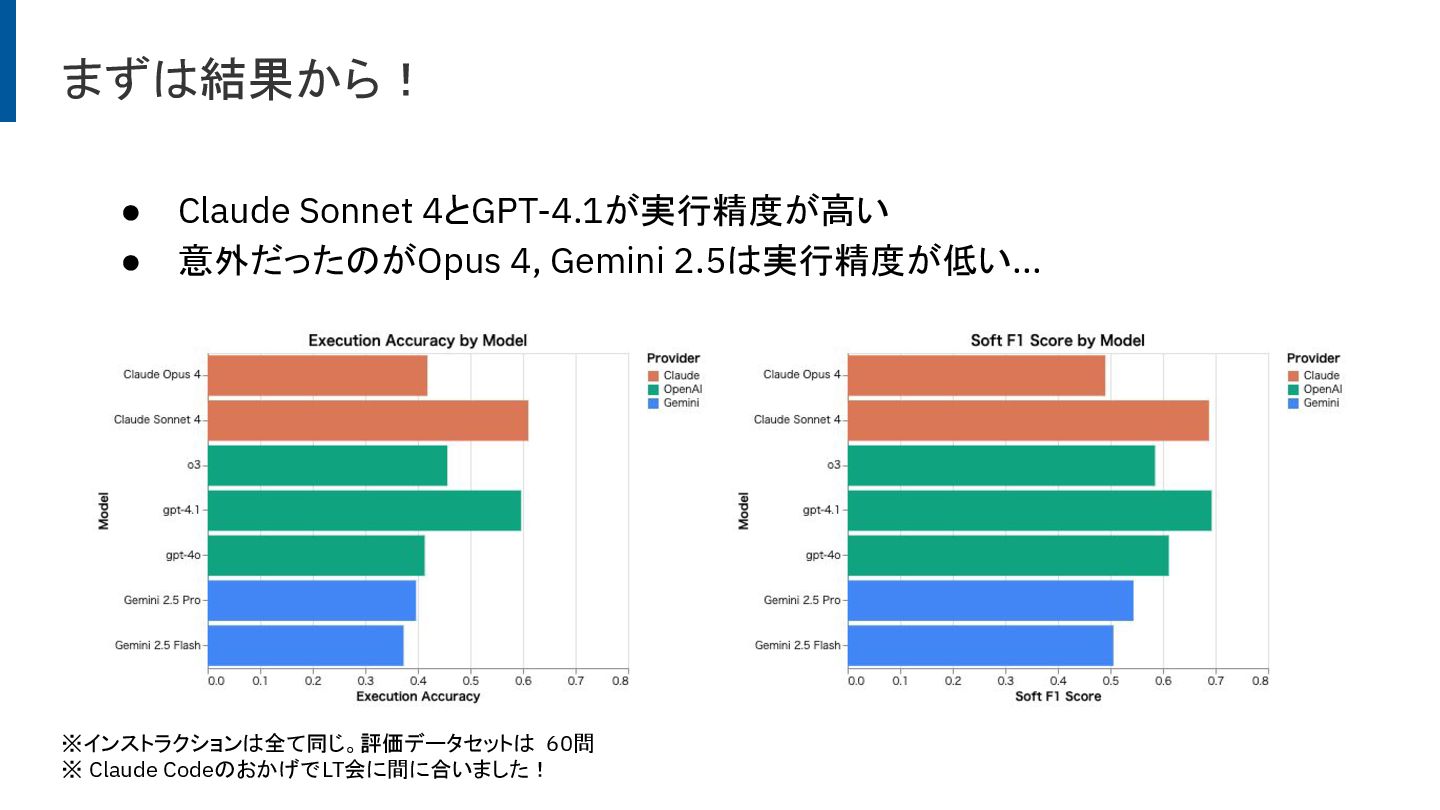 これはText To SQLの性能を評価したもので、Claude CodeのLLMモデルはなかなか性能が高いようだ。
これはText To SQLの性能を評価したもので、Claude CodeのLLMモデルはなかなか性能が高いようだ。
そこで、自然言語でこれらのCSVが分析できるほうが知りたい結果を速く知れるようになるのではないかと思い、実際にやってみた。
分析の概要
今回対象にしたのは、10ファイル(テーブル)、すべて合わせて1,000万件弱のレコードを持つデータだった。
RDBについては、SQLiteを選択した。 PostgreSQLなどサーバクライアント形式のRDBを選んでも良かったが、特にサーバー構成とか考えなくて良いのと、データベースをファイルとして扱えるし、手っ取り早く始められるのが理由。
Claude Codeでの分析手順
1. CSVファイルの読み込み
CSVファイルの前処理を実行するスクリプトファイルをClaude Codeで生成した。 今回、文字コードがShift_JISだったので、UTF-8に変換するコードを生成させた。
CSVファイルをSQLiteに読み込むためのスクリプトもClaude Codeに生成させ、実行させた。
CSVファイル名をテーブル名とし、各ファイルを .import で読み込むスクリプトだ。
.importコマンドを知らなかったので、思ったよりもスリムなスクリプトファイルが生成された。
2. データの状況確認
CSVファイルのダンプ元となったテーブルのリレーションが正しく理解できそうなのか確認するため、まずER図から生成させてみた。 生成させるER図は、ASCIIアートではなく、言語的に構造がLLMが把握しやすそうなmermaid形式にした。 事前に元のデータベースのリレーションは知っていたので、それと照らし合わせてみることにした。 結果、生成されたER図は正確にリレーションを理解できることがわかった。 これができていたのはカラム名の命名規則が統一されていたこと、CSVのヘッダがちゃんと提供されていたためだろう。
3. 分析
自然言語でテーブルの内容を分析することができた。
例えば、
テーブルAの条件Aを満たすレコードの件数、そのうちテーブルBとの関連があり条件Bを満たすレコードの件数を求めよ
テーブルXのカラムYの値の分布を求めよ
といった感じで書くことができた。 SQLの文法と分析内容の両方を考える必要があったのが、分析内容だけに集中できるようになった。 また、自然言語として多少書き方が揺らいでも分析が実行できる体験は良かった。
Claude Codeを使ってみて
良かった点
- 分析のクエリを作成する時間が圧倒的に速かった。
- 速度の要因としては、人間側としては自然言語で記述できるというのが圧倒的に楽ということもある。
工夫した点
- 分析した結果については、Markdown形式のドキュメントとしてまとめさせた。これは
CLAUDE.mdに、「分析内容、分析結果、使用したSQLを記録せよ」といったことを記述しただけで、分析を指示するごとにまとめてくれるのが楽だった。- 分析の指示をしたときに、場合によってはドキュメントを参照して、既存の結果との関連も含めて解説してくれることがあり理解を深めることができた。
難しかった点・注意点
- 時折非常に負荷のかかるクエリを生成することがあった。JOIN句を使えば良いところをサブクエリを使ってWHERE句で数百万レコードに対する冗長なスキャンが走るクエリを生成しているものが多かった。これはSQL実行の前に必ず人間のレビューを入れるように
CLAUDE.mdで制御することで抑えることにした。
まとめ
Claude Codeを使って、データベースからダンプしたCSVファイルの分析を行った。 SQLiteへのデータ投入からER図の生成、分析クエリの作成まで、自然言語で指示するだけで実行できたのは非常に効率的だった。
特に、CLAUDE.mdを活用して分析結果をドキュメントとして蓄積させる運用は、分析の履歴が残り、後から振り返りやすくなるのでおすすめしたい。
一方で、大量データに対して負荷の高いクエリを生成してしまうケースもあったため、SQLの実行前には人間によるレビューを挟む運用が必要だと感じた。 AIに任せきりにするのではなく、人間がチェックポイントを設けることで、安全かつ効率的にデータ分析ができるようになる。
データ分析においてもClaude Codeは強力なツールになり得る。SQLに詳しくない人でも自然言語で分析を進められるし、SQLに詳しい人にとってもクエリ作成の時間を短縮できる。 手元にあるCSVファイルをサクッと分析したいときに、ぜひ試してみてほしい。
